If mind-boggling complexity is the barrier to developing personalised cancer care strategies, could mathematical modelling – long used by economists, meteorologists and others – be the answer? Marc Beishon talks to leading figures who are exploring this approach.
We’re making progress of sorts in personalised medicine, as headline results at ASCO revealed, for example on certain prostate and ovarian cancers. But at the current rate, finding long-term solutions for cancer patients as a whole will take an unthinkable period of time at an unsustainable cost.
A growing number of researchers are now convinced that the radical progress we need will only be possible if we start using computational and systems biology approaches to model patients at an increasingly individual level, to determine what treatments could (and would not) work for any given person.
As Hans Lehrach, head of vertebrate genomics at the Max Planck Institute for Molecular Genetics, Berlin, comments, the biggest selling drugs – not just cancer drugs – benefit at best only a quarter of people who take them, and some as low as about 5%. “Meanwhile adverse drug reactions are responsible for more deaths than colon cancer, and generally we are paying a huge economic price because we can’t always predict who will respond to a drug. You can only really find out if a drug works by trying it on a patient – but we don’t have to do it for real. We can do it on computers where of course there is no risk to the patient.”
Lehrach is one of Europe’s leading proponents of the idea of conducting virtual clinical trials with cohorts of virtual patients, using “fantastically detailed” information now emerging on the biology of tumours and the vastly increased power of computers, which are now available at reasonable cost – certainly within the same ‘ballpark’ as efforts in other fields such as self-driving cars and computer gaming. He argues that, in the foreseeable future, it should be possible to gather such information from individuals with cancer and at least manage their disease to a much better extent than now.
Making better predictions of what will work
Lehrach emphasises, however, that this is about much more than taking a panel of gene variants and applying statistical modelling – it’s about deploying the full array of ‘omics’ information and signalling pathways of cells at a much deeper, ‘mechanistic’ and individual level. Even then such approaches will be far from perfect and many will still fail – but they will fail in a computer model instead of in live patients.
He believes that oncologists will begin to ask whether it is really appropriate to start with the blunt instrument of chemotherapy, and will instead apply treatments that address actionable targets first, especially for those with advanced disease. The aim, he says, is to model the mechanistic processes much more quickly, to make better predictions of what will work for an individual. “If we can predict therapies that will work for say 40% of patients, we will be way ahead of existing clinical practice,” he comments.
Lehrach – who is keen on analogies from other fields – says that aeronautical engineers have many equations to model how new planes will fly, for example. In medicine, other branches are paving the way: the development of drugs and combinations to manage HIV is a good paradigm, he suggests, especially as, like cancer, it is an evolutionary system that develops new resistance mechanisms. His vision is to model both patient and tumour at an individual level, as a cancer evolves, to give oncologists a much better toolkit not just for the main cancers, where there are established treatments, but also for the 25% which are rare or have an unknown primary, some of which do not have a first-line protocol.
Another analogy is long-term weather forecasting. As Lehrach and colleagues note in a paper on virtualising drug development through network and systems biology, while statistical strategies aren’t very successful in weather forecasting (and other complex systems), mechanistic models can potentially provide a way to simplify the ‘data deluge’ (Drug Discov Today Technol 2015, 15:33–40). And overcoming tumour heterogeneity, evolution and resistance may mean trying to test many thousands of drugs combinations, including drugs for other conditions that could act against cancer, which would only be feasible in virtual models.
A case in point – he cites a woman in Germany with metastatic melanoma who remained stable for a year by being treated with a drug usually used for rheumatoid arthritis. The drug was predicted by a virtual patient model to be effective based on the molecular features of her tumour. “This is the result of matching the molecular make-up of the tumour with the molecular features of a drug.” (Work by a US–UK team linking an arthritis drug with melanoma from a zebra fish model made the cover of Nature in 2011 – but it was a long way off human clinical trials.)
Moves to apply cancer drugs on a wider, mechanistic, basis as opposed to solely a tumour-specific basis are already under way. For example, the US regulator, the FDA, has for the first time approved a drug, pembrolizumab (Keytruda) on the basis of a biomarker and not a tumour’s primary location. But the modelling approach could also uncover many other drugs and combinations currently in the formulary that could have an oncology application, and trials are looking at matching patients with certain genetic markers to certain drugs (e.g. the US National Cancer Institute’s MATCH trial).
Lehrach’s vision goes further, positing a virtual patient model that could have a staggering amount of data – not only all the high throughput ‘omics’ data – genomic, proteomic, metabolic – but also taking into account a tumour’s spatial heterogeneity, as well as single cell analysis, immune status, haplotype sequencing (linked genetic markers present on one chromosome, which tend to be inherited together), and clinical information such as lifestyle and comorbidities. The reaction of patients, such as how the liver metabolises a drug, effects on normal tissue (i.e. side effects) and other interactions, as well as non-mechanistic data, such as that derived from non-drug based therapies, can also be modelled.
From single markers to comprehensive molecular analysis
Schematic comparison of the range of the approaches for molecular characterisation of tumour and patient, which span a continuum from a single marker, through to sequenc- ing a limited number of tumour genes (a gene panel), and analysis of the whole ex- ome, to combined analysis of patient and tumour using both genome and transcriptome information Source: M Schütte et al. Public Health Genomics, published online 9 June, 2017, doi:10.1159/000477157, reprinted with permission from S. Karger AG, Basel
Lehrach, who has founded a company (Alacris Theranostics) to develop virtual patient models, believes they can be used both for delivering personalised medicine in the clinic, and for drug development. His company is now leading a Horizon 2020 (European Union) programme called CanPathPro (canpathpro.eu). Described as a combined experimental and systems biology platform, it will allow users to integrate private or public data sets to predict the activation status of individual pathways, “enabling ‘in silico’ identification of cancer signalling networks critical for tumour development, as well as the generation of hypotheses about biological systems that can be experimentally validated.”
Modelling tumour and patient
This is a field where the integration with disciplines outside of biology is vital, not least computational experts and mathematicians who work in the ‘in silico’ world. A good example is the Integrated Mathematical Oncology Department at the Moffitt Cancer Center, Florida, which has recently shown how a mathematical model can work in improving the translation of preclinical findings to the clinic, co-incidentally also with melanoma (Eur J Cancer 2016, 67:213–22). They call the idea the ‘phase i’ trial, where i means imaginary (or virtual), or indeed ‘in silico’. It is a complex study that aims to create shortcuts between the in vitro/in vivo preclinical world and the vastly more heterogeneous reality of patients.
Led by Eunjung Kim, the study is a proof of concept of the idea that a mathematical model based on data from human and animal cell experiments and from existing clinical data is not only able to match what happens in an early stage drug trial but can also pave the way for better early stratification of who is likely to benefit from a therapy, potentially improving the introduction of drugs through the traditional phase I to III process.
The researchers were familiar with a phase I trial of a targeted drug – an AKT inhibitor – that was trialled in combination with various chemotherapies and with another inhibitor in patients with a range of solid tumours, some of whom had advanced melanoma. They note that a number of targeted drugs have been tested in trials either alone or with other agents, but the majority have not proved to be effective in humans despite showing promise in cell and animal models.
“His vision is to model both patient and tumour
at an individual level, as a cancer evolves”
They looked at effects of the drugs only on melanoma, by constructing a mathematical model of the dynamics of melanoma cells when they are exposed to four treatment conditions: AKT alone, AKT and combinations, chemo only and no treatment. They then carried out cell culture experiments to calibrate the model, and validated it further with a series of cell experiments that predicted the effects of 12 different drug combinations and timings.
Then comes the key part: they generated a cohort of virtual patients according to the clinical trial results. In fact, using a genetic algorithm of tumour volume they produced a virtual patient population of over 3,000, and a sample of 300 of these matched responses seen in the real trial, where just 24 patients had melanoma (out of a total of only 72). From this they were able to show what treatments and schedules would give certain patients the most favourable (and less favourable) outcomes. As the authors note, one of the key limitations of preclinical in vitro cell studies is their short duration; one of the benefits of the phase i idea is that it can show what the likely longer-term effects on patients will be.
“The phase i trial aims to create shortcuts between the preclinical world
and the vastly more heterogeneous reality of patients”
This is the basis of phase i, which they also say is not a new idea in essence – there have been simulations in other areas such as in cardiovascular disease, and modelling that has used statistical approaches based on drug metabolism. Their proof of concept study goes a lot further, however, by taking the biological mechanisms seen in cell studies and making a potentially major (and complex) leap into the clinic.
Alexander ‘Sandy’ Anderson, head of the mathematical oncology department at Moffitt, and a co-author, points out that they had to make a big assumption in the study, namely that there is a key resistance mechanism in play that gives rise to the response differences. “We know patients have a variety of responses owing to resistance, from good to partial to none, and in this case we focused on a mechanism called autophagy, which we assumed is the same we would see in patients, based on a study from the trial. In fact, patients probably have multiple resistance mechanisms, which could be incorporated into a more complex model, but this one alone allows us to make useful predictions.”
Put simply, autophagy is a survival-promoting state that can allow tumour cells to survive drugs, but in some circumstances can provoke tumour cell death – a paradoxical finding that has prompted researchers to test drugs that can affect autophagy, including AKT inhibitors.
The Moffitt researchers knew from the real trial that two patients with a certain genetic variation had unexpected long-term responses to the AKT inhibitor combined with chemotherapy, and had reasoned this was due to a differential effect of inducing autophagy. From the cell experiments they could see that the metastatic melanoma cells became autophagic and resistant under the AKT/chemo drug combination, but they also identified two states of autophagy, one of which, when in a persistent state, leads to cell death and more favourable outcomes.
A machine-learning approach
What the model does, Anderson explains, is use an automated, machine-learning approach to find sets of parameters from the experiments that mimic patients’ responses, each one being a virtual patient. As the parameter sets can vary greatly, they ended up with more than 3,000, which was sampled and stratified into degree of response. “Then we can go back and see what it is about the underlying mechanisms that make them good or poor responders – in other words, the most important parameters that drive the stratification.”
From this they were able to show what treatments and schedules
would give certain patients the best outcomes
In this case, he says, there are two parameters that appear to stratify well – the proliferation rate of the tumour cells, and the rate at which cells become autophagic. “If we can measure those in a real patient – and it is realistic to measure the autophagic fraction from a biopsy and monitor the cell doubling rate – that will give us a way to select and treat patients who are likely to respond better at the phase II and later stages of a drug trial.”
Anderson adds that there is a striking finding: they found almost no overlap of the main parameters in the model between the cell lines and patients. “So if you were to assume the response of the patients would be the same for the same dosing and scheduling as with the cell lines you wouldn’t get a good result,” he says. The point is that this finding helps to explain why preclinical results are so often not replicated in patients.
What is important about virtual patient modelling is that parameters can then be varied, including dose amounts, when to apply drugs (in sequence or together), and also applying a treatment ‘holiday’ – stopping and restarting a drug. In the study, the authors report that using a lower dose of the AKT inhibitor is better in some cohorts, and that “changing the temporal protocol influenced the dynamics of the system significantly.” These variations cannot all be trialled in early phase trials or later trial stages, even when fairly large numbers of patients are enrolled.
Indeed, most preclinical data are based on individual drugs. Trials of the sorts of combinations that are becoming so important in oncology are mostly carried out at the phase II/III stages, so these virtual models are likely to become increasingly important, although new preclinical research may be needed, as with the Moffitt work. And such mathematical modelling is not confined to in vitro studies, but can also apply to human only ones, as the authors note about a study of radiation dosing schedules for brain tumour patients (Cell 2014, 156:603–16).
“We can see what will change after a drug is used –
and what secondary therapies will work best”
Anderson notes that the combination therapy in the AKT trial was not taken forward owing to mixed results, but that if the stratification his team has found is used, it could identify a subset of patients who are very responsive. He also mentions an (unpublished) simulation they did as part of the study, to see whether autophagy inhibitors other than AKT could help poorer responding patients – candidates could include drugs usually used to treat malaria, in an echo of the ‘repurposed’ arthritis drug mentioned by Lehrach.
Adaptive therapy to address resistance
Jacob Scott, a physician–scientist who coined the term ‘phase i’ when he was at Moffitt, says that a critical part of the data discovery process that can feed into modelling is to understand much more about the evolution of tumours and how they develop resistance to drugs. Now working in his own lab, at the Cleveland Clinic, Ohio, this is his current focus. “By figuring out what we call the tumour ‘sensitivity network’ we can see what will happen after a drug is used – what will change in the tumour, and what secondary therapies will then be most beneficial. This is very different from just determining the current weakness of a cancer.”
In a paper recently published in Scientific Reports (2017, 7:1232), Scott and colleagues have mapped a way to predict which of the new generation of ALK inhibitors in non-small-cell lung cancer could be the most sensitive agents to use at second line, once the initial drug inevitably fails (the key is avoiding cross-resistance among agents and getting the length of drug cycles right, including using drug holidays).
This growing understanding of the evolutionary nature of cancer may mean oncologists will be in a position to at least manage a chronic disease, if not effect a cure. This has long been mooted, but has so far proved elusive in all but a small proportion of patients with metastatic disease.
Both Scott and Anderson mention work on cancer evolution by Charles Swanton at the Francis Crick Institute in London, which is looking at how distinct populations of cancer cells arise within the same tumour – and what we can do about it (see for example Nat Rev Drug Discov 2017, doi:10.1038/nrd.2017.78, and Using Darwin’s Notebook to Outsmart Resistance, Cancer World 77, 3 March 2017).
Anderson agrees that resistance mechanisms are crucial, noting the concept of competitive release, whereby resistant cells are initially outcompeted by sensitive cells because they are less ‘fit’, but then become competitive and take over when a drug eliminates the sensitive population.
He points to a trial now underway at Moffitt, which seeks to address this mechanism of resistance using what is known as ‘adaptive therapy’. This involves using a mathematical model to schedule treatments for prostate cancer by stopping and starting anti-hormone therapy based on PSA levels and tumour burden.
He adds that the principles are similar to the phase i strategy, of moving away from a ‘dose-dense’ approach of applying fixed therapies, to instead finding the best ways of delivering drugs and combinations as a cancer evolves, especially at the metastatic stage. And the virtual patient concept is certainly part of the picture: “We can apply it not only to heterogeneity in a population, but also to uncertainty about a single patient, with a virtual cohort that has all the known aspects of that patient in common and all of the unknown aspects spread throughout the cohort. If we can treat the cohort we have a good chance of treating the patient.”
The idea of integrating the power of modelling, biological mechanisms, and evolutionary insight to open up an extensive toolkit for an individual patient – essentially a clinical trial for one person – is now being seriously considered, and would be a huge step on the road to precision medicine. But it needs resourcing – and if Lehrach had his way, we’d see the same sums going into cancer models as are now spent on computer games – society has its priorities seriously wrong, he feels.
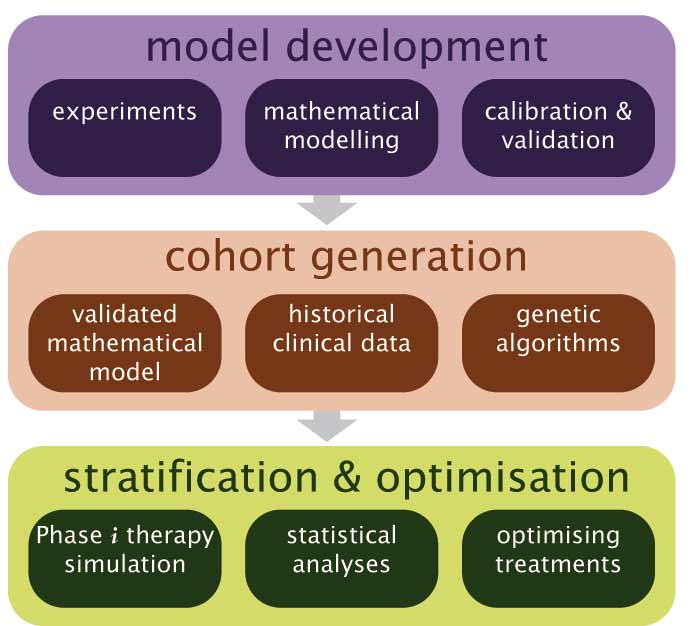
Phase i trials
Step 1. A mathematical model is developed based on experimental data. The model is then calibrated and validated by comparing model prediction and experimental results.
Step 2. The validated model and genetic algorithms are used to generate a virtual cohort that statistically matches historical clinical data.
Step 3. Phase i therapy, assuming the same schedules in a clinical trial, is simulated using the cohort. The virtual cohort is analysed to predict stratification factors. Optimisation approaches are employed to propose optimal therapy, which may guide better patient selection and treatment strategies in subsequent clinical trials
Source: E Kim et al (2016) Eur J Cancer 67:213–222. Reprinted with permission from Elsevier




 He believes that oncologists will begin to ask whether it is really appropriate to start with the blunt instrument of chemotherapy, and will instead apply treatments that address actionable targets first, especially for those with advanced disease. The aim, he says, is to model the mechanistic processes much more quickly, to make better predictions of what will work for an individual. “If we can predict therapies that will work for say 40% of patients, we will be way ahead of existing clinical practice,” he comments.
He believes that oncologists will begin to ask whether it is really appropriate to start with the blunt instrument of chemotherapy, and will instead apply treatments that address actionable targets first, especially for those with advanced disease. The aim, he says, is to model the mechanistic processes much more quickly, to make better predictions of what will work for an individual. “If we can predict therapies that will work for say 40% of patients, we will be way ahead of existing clinical practice,” he comments.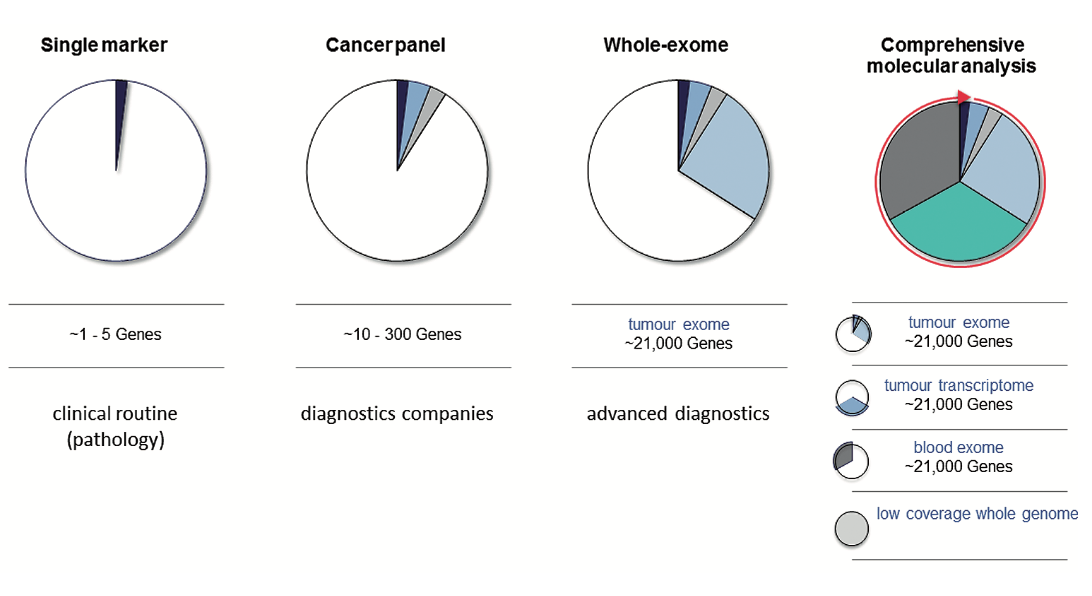



Leave a Reply