


Some scholars recently coined the expression “Medical Misinformation Mess” to describe current clinical medicine as a realm in which it is very difficult to evaluate both reliability and practical meaning of research studies. A realm in which most actors – patients, families, and also medical professionals – don’t even realize how hard is the challenge they are facing. It’s a mess in which the different attempts at fine-tuning the use of statistics for biomedical studies include both proposals for raising the bar of statistical significance – independently of other factors – and the exact opposite, specifically when evaluating new cancer therapies that appear to be promising.
This Medical Misinformation Mess clinicians need to deal with

«Currently, there are nearly approximately 17 million articles in PubMed tagged with “human(s)”, with more than 700 000 articles identified as “clinical trials”, and more than 1,8 million as “reviews” (approximately 160 000 as “systematic reviews”). Nearly one million articles on humans are added each year» writes biostatistician John Ioannidis in an analysis published on the January issue of the European Journal of Clinical Investigation, where he is Editor in Chief. «Popular media also abound with medical stories and advice for patients. Unfortunately, much of this information is unreliable or of uncertain reliability. Most clinical trials results may be misleading or not useful for patients. Most guidelines (which many clinicians rely on to guide treatment decisions) do not fully acknowledge the poor quality of the data on which they are based. Most medical stories in mass media do not meet criteria for accuracy, and many stories exaggerate benefit and minimise harms».
Ioannidis, who currently co-directs the Meta-Research Innovation Centre at Stanford, was criticized in the past for his choice of controversial angles and catchy titles (his 2005 paper on Plos Medicine on “Why most Published Research Findings are False” is among the top most-accessed articles in the history of the Public Library of Science with almost 2,5 million online views), but is far from being alone: in recent years, more and more evidence on how the low methodological quality of most biomedical research has caused the so-called “non-reproducibility crisis” has been accumulating.
Highly cited, so what?
Speaking in general, it is quite difficult to judge the quality of a researcher’s work: an in-depth evaluation requires knowledge of the specific field of research, methodological skills, access to the protocols and the raw data, and a lot of time. That’s why reliability is usually based on proxies, such as the evaluation by peer-reviewers and then the appreciation within the scientific community as measured by bibliometric indexes like number of citations, impact factor (derived from citations) and so on.
Publication is just the first step in a long validation process that still requires replication, but a similar assumption about reliability is made even when the research has just been published, based on the historic performance of editors and peer-reviewers of each journal.
This plausible assumption has no real scientific basis, and according to a review article in the February issue of the open-access journal “Frontiers in Human Neurosciences” is wrong. Neurobiologist Björn Brembs, from the University of Regensburg in Germany, investigated the differences between the top-tier peer-reviewed journals – those that tend to attract more citations and are hence associated to the highest “impact factor” – and the rest of the pack, concluding that the methodological quality does not increase with increasing rank of the journal: «On the contrary, an accumulating body of evidence suggests the inverse: methodological quality and, consequently, reliability of published research works in several fields may be decreasing with increasing journal rank» explains Brembs.
A new acronym for p-value

CREATIVE COMMONS ATTRIBUTION-NONCOMMERCIAL 2.5 LICENSE.
Sitting on the bench of the accused in a prominent position is the misuse of the p-value, a statistical tool that currently might be considered the holy Grail of quantitative research. «P values have always had critics. In their almost nine decades of existence, they have been likened to mosquitoes (annoying and impossible to swat away), the emperor’s new clothes (fraught with obvious problems that everyone ignores) and the tool of a “sterile intellectual rake” who ravishes science but leaves it with no progeny. One researcher suggested rechristening the methodology “statistical hypothesis inference testing”, presumably for the acronym it would yield» jokes science writer and statistician Regina Nuzzo, whose 2014 feature article on Nature Magazine («Scientific Method: Statistical Errors») rapidly became the most viewed among Nature articles. «The irony is that when UK statistician Ronald Fisher introduced the P value in the 1920s, he did not mean it to be a definitive test», she adds.
Nuzzo, who also teaches statistics at the Gallaudet University in Washington DC, was the facilitator of a workshop organised in 2015 by the American Statistical Association (ASA), who convened some among the best statisticians for two days with the goal of setting the record straight on p-values, and their use in research. The practical result was disappointing: besides theoretical definitions statisticians can agree on, the correct use of p-values is still a matter of heated debate. For sure, the statement published by ASA made it clear that misunderstandings and misuses are widespread. «These are pernicious problems» said Boston University epidemiologist Kenneth Rothman. «It is a safe bet that people have suffered or died because scientists and editors, regulators, journalists and others have used significance tests to interpret results, and have consequently failed to identify the most beneficial courses of action».
Rothman was not among the 72 prominent statisticians who in 2017 proposed with Ioannidis, who calls it «a quick fix», to raise the bar for statistical significance: «Lowering the standard P-value from <0,05 to P <0,005 can reduce the high rates of false-positives that even in the absence of other experimental, procedural or reporting problems end up contributing to the lack of reproducibility» he says.
Cancer research is hard to reproduce
The strong alarm on the lack of reproducibility in preclinical cancer research went off in 2012, when Nature magazine published an article in which Glenn Begley and Lee Ellis reported the attempts by several researchers in companies like Amgen and Bayer at repeating crucial experiments in many «landmark» studies, mostly failed. Their analysys – which was unusual and brought criticism to the journal for citing the lack of reproducibility without mentioning specific studies and without providing identifiable details – was rapidly followed by the launch, in 2013, of the Reproducibility Project: Cancer Biology. Its first attempts were worrying, with only 2 studies out of five fully reproduced, but the following round of studies yelded a more encouraging result.

«A crucial step is to move beyond the alchemy of binary statements about ‘an effect’ or ‘no effect’ with only a P value dividing them» summarised statistician Andrew Gelman, who directs the Applied Statistics Center at Columbia University, in a short comment published on Nature at the end of 2017 (Five ways to fix statistics). «Instead, researchers must accept uncertainty and embrace variation under different circumstances».
One of the circumstances that should suggest to embrace variation might be when dealing with terminally ill cancer patients who have little or no therapeutic options available: «Such patients may prefer to take a bigger chance on a false-positive result, even if the likelihood of an effective therapy is small. To quote the noted biostatistician Donald Berry, “We should also focus on patient values, not just P values”» argues Vahid Montazerhodjat, from the Laboratory for Financial Engineering of the MIT Sloan School of Management (Jama Oncology 2017). «Traditional RCTs do not necessarily minimize overall harm to current and future patients, especially for life-threatening cancers that currently have no effective therapies. In these cases, traditional RCTs are too lengthy, too conservative, and focused too much on rejecting ineffective drugs and avoiding false-positive results. This single-minded focus can result in missed opportunities to treat life-threatening conditions, which can sometimes harm more patients than mistakenly approving ineffective and possibly toxic drugs».
«Montazerhodjat et al. take issue with the p-value, arguing that regulators’ insistence on a significance level of p<0,05 is often too conservative» reply Robert Kemp and Vinay Prasad. In the case of metastatic pancreatic cancer, for instance, the authors advocate lowering the hurdle to p<0,20. Not only is this a bad idea, because it increases the chances of “false positives” flooding the market, but it misses the point that the current system, even with a more stringent p-value cutoff of p<0,05, is already frequently rigged in favour of sponsors in a way that ultimately leaves patients with approved drugs for which there is still substantial uncertainty of actual clinical benefit».
«As a matter of fact» they conclude on the online pages of The BMJ «the current regulatory system tolerates a high degree of uncertainty that our interventions benefit the patients in whom we employ them. We favour efforts to understand and quantify this uncertainty, but for the time being, are reluctant to embrace proposals that enhance it. If anything, we believe the uncertainty for patients should be reduced, and the use of surrogates as well as uncontrolled studies should remain the exception to cancer drug approval and not the rule. Cancer patients vary in their willingness to tolerate risk, and the current approval structure already makes many costly drugs available whose benefit is anything but certain. Loosening standards is the wrong direction for reform».
How valuable is p-value?
An analysis of millions of peer-reviewed articles published between 1990 and 2015 showed in 2016 that p-values – despite the high risk of misuse and misunderstandings – has not only colonised journals, but has done so at the expenses of better metrics of effect size or uncertainty, reveals a study led by French mathematician David Chavalarias, director of the Complex Systems Institute of Paris, published on Jama in 2016.
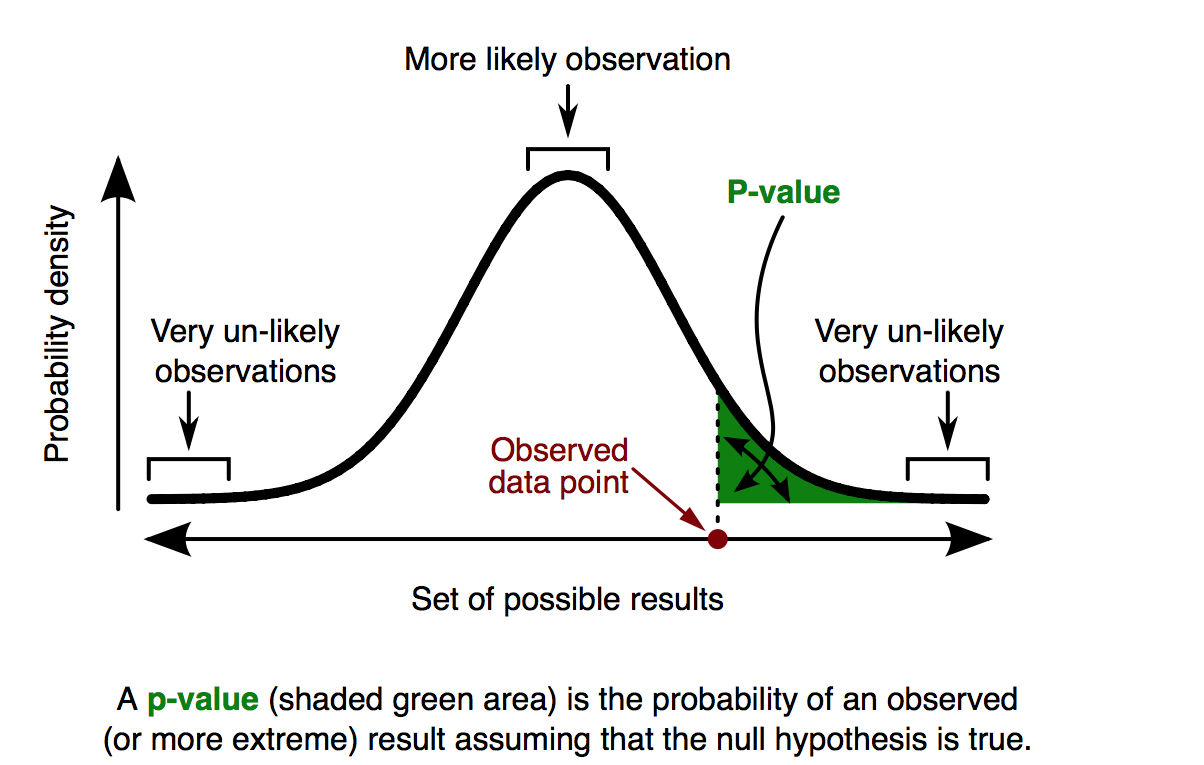
P-values are used to estimate the role chance may have in determining results. When a clinical trial shows that drug A is 20 percent more effective than drug B, the p-value estimates how likely it is that the difference between the effects of drugs A and B is due just to chance. In other words, how likely it is to get these results if a “null hypothesis”— in this case, that there is no difference between the two drugs – were true.
If drugs A and B are equally effective, a study with a p-value of 0,05 executed for 100 times will conclude in fives cases that drug A is at least 20 percent more effective. «The exact definition of p-value is that if the null hypothesis is correct, the p-value is the chance of observing the research result or some more extreme result» explains Ioannidis, who was a co-author of the study. «Unfortunately, many researchers mistakenly think that a p-value is an estimate of how likely it is that the null hypothesis is not correct or that the result is true».
Regina Nuzzo, who also teaches Statistics at the Gallaudet University in Washington, has been looking for a simple definition, that could help everyone understand better: «The best definition I found is that p-value is an index of surprise: how surprised I would be to find results as extreme or more extreme, if the null hypothesis is true».
See also:
Too high or too low? ESMO’s clinical benefit scale fuels debate over approval thresholds
Systematic reviews – your key to evidence-based medicine
Why most clinical research is not useful


Leave a Reply