For a disease that has led the field of molecular biology, it is surprising perhaps that so few biomarkers have been identified that can predict a person’s risk of developing cancer. Researchers are now looking at what genetics and epigenetics can add to traditional risk factors such as age, weight and family history, and at how to refine the way we interpret and use the data. Marc Beishon reports.
The rise of the ‘omics’ – especially genomics and epigenomics – has fuelled interest in stratifying people’s risk of developing cancer. Virtually every tumour type now has research programmes that are identifying increasing numbers of variations associated with raised or lowered risk, to add to other biomarkers and lifestyle and environmental factors.
It is part of the drive towards personalised medicine and the goal of targeting interventions such as more frequent screening, a preventive drug, or help with lifestyle changes, to those at highest risk, while reducing overdiagnosis and the stress and costs associated with screening, for those at lowest risk.
But while there are some obvious major risk factors such as smoking and radiation, unlike in other fields such as cardiovascular disease there has so far been limited utility for molecular biomarkers as indicators of risk, and genomic data has only added small refinements to existing risk prediction models.
This is not holding back research, judging by the volume of studies, many of which are high quality, especially in the genomics field.
“We had of course known for years before about the small proportion of women who are at very high risk and are managed in family cancer clinics, before and after the BRCA genes were discovered. But our paper showed that there is also a distribution of inherited risk in the population and it might be possible to focus screening on those at higher risk to maximise the benefit–harm ratio.”
By 2007, Pharoah and others around the world had identified a handful of common genetic variants associated with breast cancer from genome-wide association studies (GWAS). Today, more than 150 variants have been identified for breast and also for prostate cancer, which are helping refine risk models – so called ‘polygenic’ risk.
Major contributors to this work include the EU-funded Collaborative Oncological Gene-environment Study (COGS), which focused on genetic determinants of breast, ovarian and prostate cancer, and, more recently, the international OncoArray project, which is looking at a wider group of cancers, and is just beginning to publish its first papers.
Pharoah comments that there has been considerable pressure from funders to demonstrate the value of the genomic work. “The pressure on us is huge – research funders rightly expect that our research should have clinical translation,” he says. “But we have been getting better at risk discrimination and we have shown that, while other factors can be good risk predictors, by adding germline data in combination we have better models. For example, we can say that about 20% of 50 year old women have less than half a per cent risk of dying from breast cancer in their lifetime, so the benefit of screening is very small. And that’s a lot of women.”
He stresses that there is no evidence that genomic data is, or will be, superior in terms of determining risk, and indeed at present simply asking about family history can tell us almost as much as all the known common genetic variants, although he makes the point that “the great advantage of genetics is that it can be measured incredibly accurately with almost no bias.”
But the search for other biomarkers in the field of molecular epidemiology has been a disappointment in breast cancer, although there is some promise in hormones, and there may well be advances to come, while breast density, on the other hand, is proving to be a significant factor. “We may also be coming to the limits of what we can refine using genomic data – larger and larger studies are needed to find things with smaller and smaller effect,” says Pharoah.
Biomarkers of cancer risk
Efforts to identify biomarkers that reliably indicate risk of developing cancer have so far proved disappointing. The one exception may be testing for infection with cancer-causing types of the human papillomavirus (HPV).
As cervical cancers almost never occur in the absence of HPV infection, testing for the presence of cancer causing types of the virus can identify people not currently at risk. A recent study in the Netherlands, for example, suggests that the interval between screenings could be extended safely from 5 to 10 years for women aged 40 and over who test negative for HPV DNA (see BMJ 2016 355: i4924, and ‘HPV Faster’ Cancer World Jan–Feb 2017).
Viral and bacterial linkages with cancer, including HPV, hepatitis B/C, Helicobacter pylori and others, are spawning a new field called metagenomics.
Biomarkers including PSA for prostate cancer and CA125 for ovarian are also important in risk stratification, although a distinction is that they are primarily diagnostic, and indicate suspicion for an existing cancer, which may require further testing.
How strong is the signal?
The degree of ‘discrimination’ in determining risk is a critical factor. It measures the probability to which a model will distinguish between those who will go on to develop a disease from those who will not, and so varies from 0.5 (which would just be flipping a coin) to 1.
The well-known Gail breast risk model, which takes into account factors such as family history, age and weight, age of first menstrual period, whether the woman has had children, whether she has gone through the menopause, and if she is a current or past user of hormone replacement therapy, has a discrimination of 0.55, but this can rise to 0.71 once single nucleotide polymorphisms (SNPs) and breast density are added to traditional risk factors.
But Nora Pashayan, clinical reader in applied health research at University College London, points out that, although adding polygenic risk data and more non-genetic risk factors to models like Gail may result in only modest increase in discrimination accuracy, the impact could be more substantial in stratifying the population into different risk groups (for a technical explanation see JNCI 2014, 106: dju305).
“There is though also trade-off between improving discrimination accuracy and the user-friendliness of a model. In particular, as information on more non-genetic risk factors is needed, the more difficult it is to get complete and accurate information about them. It’s why I am researching epigenetic markers that can be used as proxy for these risk factors to improve both the accuracy and ease of use of models.”
Four cancers, one predictive test
Epigenetics is at the centre of one of the most ambitious risk stratification projects yet, now looking to individualise screening and prevention for not one cancer, but four women’s cancers – cervical, breast, endometrial and ovarian, which comprise nearly half of all cancer cases in women.
FORECEE is a four-year project launched in 2015, involving 13 European institutions, and led by surgeon Martin Widschwendter, professor of women’s cancers at University College London (UCL). An EU Horizon 2020 project, it is developing a predictive test for all four cancers from a number of markers taken from a standard cervical smear, as well as from blood and cheek swabs, with different tests for pre- and post-menopausal women.
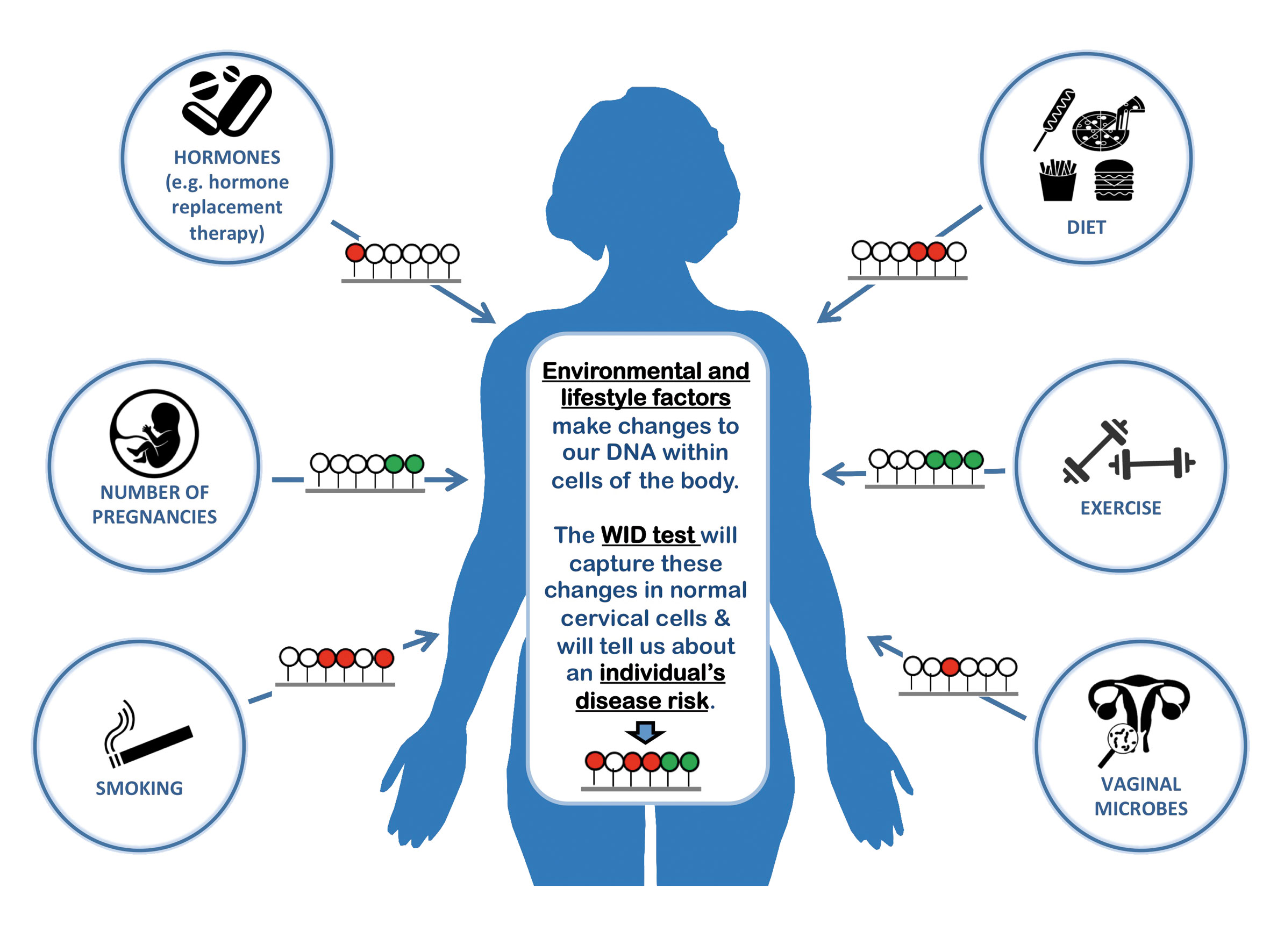
The WID risk test for four women’s cancers
(click to enlarge)
The Women’s cancer IDentification (WID) test, which is under development, uses cervical cells to detect epigenetic and metagenetic changes that go beyond genetic mutations (such as BRCA), to identify DNA changes associated with cancer risk that have occurred through environmental and lifestyle factors (red= raising risk, green=lowering risk). This information could be used to provide women with personalised risk prediction of developing cancers of the breast, cervix, uterus and ovaries over the following 10 years.
The ambition is revealed in the inclusion not just of genetic data but also epigenetic and ‘metagenetic’ markers – the former being non-inherited changes due to lifestyle and environment (with the DNA methylation process being the key mechanism studied), and the latter viral and bacterial features, as with HPV.
The rationale seems straightforward – all these women’s cancers have similar epidemiological and genomic risk factors and, as Widschwendter says, the most aggressive tumours such as triple negative breast and high grade serous ovarian and endometrial cancers “have a stunning molecular similarity”.
Cervical cells are easy to gather from routine smear tests, and the researchers hope to show they contain markers that can be used to raise the bar in risk prediction for all the cancers. For example, in ovarian cancer, the largest ever screening trial, the UK Collaborative Trial of Ovarian Cancer Screening (UKCTOCS), recently reported encouraging evidence of a mortality reduction, but the researchers say that while the extent of the reduction is further explored, efforts to improve risk stratification and also markers will also be needed.
“By adding germline data in combination with other factors we have better risk prediction models”
Pashayan, who is a co-investigator in FORECEE (and also in breast and prostate risk projects in Canada and the US), says that the inclusion of epigenetics using cervical cells is a big step up. “When you ask about smoking and weight history, for example, you only get incomplete information – epigenetics not only measures the association of factors like these with DNA, but shows how they interact in one group, not just in silos.”
The key point is that epigenetic changes far outweigh most genetic changes in cancer. In presentations, Widschwendter uses the example of smoking and DNA methylation to show how the concept can work in other cancers, both to stratify risk and to monitor prevention (given that stopping smoking starts to reverse changes to the genome).
It is also possible to make faster discoveries with genome-wide epigenetics than with SNPs from DNA, adds Pashayan, as working out the function of the latter takes time. As all four women’s cancers are epithelial and hormone-sensitive, cervical cells offer tissue that is specific for markers of all. (Validation of epigenetic markers is being undertaken by a Swedish biobank of cervical samples, and cheek cell swabs are also taken as non-hormone sensitive controls.)
The project is also collecting and studying tumour samples (for more about how the epigenome works in cancer, see ‘Integration of genetic and epigenetic markers for risk stratification: opportunities and challenges’ – Per Med 2016, 13:93–95).
FORECEE researchers are confident that they will be able to develop better predictive tests based on prospectively collected samples and validated against a large cohort. The tests, which they have called Women’s cancer IDentification (WID), will aim to improve the smear test’s potential to detect risk of cervical cancer in pre-menopausal women and identify BRCA mutations, given that some women with these mutations are not currently picked up in family histories. In post-menopausal women, risk prediction of all four cancers is the aim: epigenetic changes accumulate over time, and these data will be combined with genetic profiling and usual factors such as weight and age.
A cautionary note is sounded by Pharoah, though, who says epigenetics has been studied for some time, and “there is a feeling that if there was something major we would have found it by now.”
Widschwendter counters that epigenome-wide association studies (EWAS) – the equivalent of GWAS – are about to evolve. “It is true that DNA methylation and other epigenetic changes have been studied in disease tissues, such as comparing cancer tissue with normal tissue, but not in normal surrogate tissue with the intention to predict future risk.”
FORECEE is important not just because of the science it is generating, but also for the raft of practical, ethical and legal issues surrounding risk prediction testing. As an EU project it is further developing these issues following the COGS project, which set out the scope.
At a recent workshop held in Berlin, at the home of the Harding Center for Risk Literacy, a FORCEE project partner, participants heard about the results of a survey of women in five countries, which explored their beliefs about and attitudes to the WID test.
The workshop also presented snapshots of country health systems and discussed the overall ethical and regulatory aspects of epigenetics, as well as issues surrounding the practicalities of introducing a complex test and the implications for insurance – in the US, for example, there are moves that could force people to disclose not only their own but their family’s health records in workplace wellness schemes.
All these topics could have a major impact on the acceptability and feasibility of introducing yet more tests that could be offered to most women at various life stages, and no one has all the answers – brainstorming was a major activity at the workshop.
Inez de Beaufort, professor of healthcare ethics at the Erasmus Medical Centre, Rotterdam, in a talk on ethics, said that when introduced to FORECEE, women may not have associated lifestyle factors such as smoking with women’s cancers, and there could be feelings of guilt and blame from others – and more than that aimed at men.
“And it’s not just your health but the health of future generations,” she said, noting the phenomenon of epigenetic inheritance. People should also feel free to take some risk in their lives, she said, so how far should health services try and intervene? Will there be services to help people after they have been tested? People are now bombarded with risk information and navigating yet more could be hard.
“Epigenetics not only measures the association of environmental/lifestyle factors with DNA, but shows how they interact”
But there are also ethical issues in not giving people information about risk. Paul Pharoah says that he expressed surprise 15 years ago that women taking part in the UK breast screening programme were not informed if they were at low risk, and comments that they are still not being told about breast density and risk.
“It would be unthinkable that when you had your blood pressure or cholesterol tested you would not be told about what they mean for future risk, and indeed it would be deemed unethical,” he says. He suggests that there may be concerns that the breast screening programme could be undermined if women who were told they were at low risk decided to stop attending.
“Since then we have had the major debate about the benefits of breast screening,” he continues. “But despite this, there still seems to be unwillingness to really evaluate the potential of cancer risk stratification properly.”
Risk is a seemingly simple word, but in the cancer world it is loaded with enormous scientific and societal connotations.
Risk stratification – further reading
A good summary of the issues was published in 2014: ‘Stratified screening for cancer: recommendations and analysis from the COGS project’ (PHG Foundation, Cambridge)
Latest research by Rosalind Eeles and colleagues for the NCI Genetic Associations and Mechanisms in Oncology (GAME-ON) initiative has found more SNPs associated with early onset and aggressive or indolent prostate cancer. They say men in the top 1% of a genetic risk score have a nearly six-fold higher risk for developing the disease compared with the median risk group (JCO 2017, 35(6S) abstract 1)
Risk stratification is also a widely used term in stratifying treatment after diagnosis, and it also extends to survivorship. For a paper on personalised cancer follow-up, see BJC 2012, 106:1–5
Researchers in Spain have put forward a new risk model for colorectal cancer in the Spanish population. They find that modifiable risk factors have a stronger value for risk prediction than genetic susceptibility (Scientific Reports 2017, 7:43263)
Newly established blood DNA methylation markers that are strongly associated with smoking might open new avenues for lung cancer screening, reports a paper from 2016 (Clin Epigenetics 2016, 8:127)
Metagenomics has broadened the scope of targeting microbes responsible for inducing various types of cancers – see Meta Gene 2015, 5:84–89
1 Comment on What can ’omics add to personalised risk assessment?
Prediction with all tools we have today will led to a Gauss curve and a statistical prediction, with nevertheless the individual not fitting to them because he has some molecular data we don’t know so far and they are endless!





Prediction with all tools we have today will led to a Gauss curve and a statistical prediction, with nevertheless the individual not fitting to them because he has some molecular data we don’t know so far and they are endless!