


Digital pathology allows pathologists to diagnose and analyse tissue samples using digital images. The technology has the potential to improve diagnostic accuracy, speed up the diagnosis process, and enhance collaboration among clinicians. With the rise of artificial intelligence in healthcare, digital pathology is becoming even more powerful, enabling pathologists to leverage machine learning algorithms to detect patterns and make accurate diagnoses. In cancer diagnosis, digital pathology and AI can revolutionise the way pathologists identify and classify cancer cells, leading to more personalised and effective treatment options for patients. Some of these innovations were discussed for specific tumours by three expert panellists in this sixth webinar of the SPCC Educational Project on Artificial Intelligence in Cancer Care 2022, which took place on 20 March 2023, and was chaired by Giancarlo Pruneri, IRCCS National Cancer Institute, Milan, Italy.
Digital pathology and AI applications for histopathological diagnosis and risk stratification
Catarina Eloy is Head of the Pathology Laboratory of IPATIMUP, Researcher at i3S, Affiliated Professor of Medical Faculty at Porto University, and Vice-president of the Portuguese Society of Anatomic Pathology, Porto, Portugal. The near future for digital pathology and AI is very promising, many changes are happening in this field and expectations are high. Expert consensus is overall positive regarding the implementation of AI resources, but we must remember that many of the new tools and technologies are not as yet mature for blind clinical usage. Our pathology labs are still following a 19th century paradigm. We have many manual processes with their inherent issues. Even the new generation of instruments has obsolete designs. We need more standardisation and automation. Penetration of digital transformation is still low. And we need a new quantifiable chemistry to obtain better performance with biomarkers, etc. In other words, the technology is here, but we need to get ready for it.
Quality is a crucial starting point. If we have good quality material in our pathology labs, we’ll probably have good conditions to perform computational analysis, and this includes the usage of AI tools. The same applies for metrology. Metrology is a science that does not collect many fans among pathologists, but if we start using it in our labs, we can achieve the level of standardisation and quantification needed for an unbiased AI performance. We must rethink the way we run our pathology labs with simple things such as using a lean approach, doing measurements and quantification of the processes so that we can achieve standardisation. Validation and calibration policies should be in all our practices as well as an error-detection oriented plan of action. Time is also crucial. We cannot forget our obligations to our patients, which include respect for the turnaround time. The system needs to be fast, the faster the better. Poor laboratory information systems are one of the major obstacles for implementation of an effective quality control system. The same applies to tracking systems. A vast number of labs do not track their samples. The same, again, for production control. If we do not control what we are producing, how can we know we are making the best quality whole slide images for computational pathology?

We must have innovative interventions in all workstations of the pathology laboratory, as well as before and after the analytic process. Clinicians need to help pathologists by providing very good material with pre-analytical conditions, to avoid issues during the standardised processes. All steps should be balanced, not just the whole slide image production. A very good whole slide image (WSI) enables us to use its plasticity, share, work remotely, ask for second opinion, and move forward to computational pathology and AI. The utilisation of AI techniques to extract all the data present in a basic tissue section stained with haematoxylin-eosin (H&E) signifies a genuine epistemological revolution. This includes the use of computer-aided diagnostic tools for diagnosis, staging, or extraction of other prognostic relevant data based on morphology (Quantification). Additionally, it opens up avenues for research, such as identifying the causal agent or pattern of a disease (Taxonomy), and the development of algorithms that can predict molecular biomarker status, which can be useful in selecting appropriate therapy (Markers).
Prof. Eloy’s group has published a number of papers that show what precise CTs can achieve. We have the capability to employ deep learning techniques to analyse morphological characteristics and extract features from basic H&E stains, such as predicting PD-L1 status. As other research groups have demonstrated, we can assess mutational status through the use of radiology images, including tomography, as well as H&E staining. This is particularly useful for triage purposes. However, it should be noted that these features have not yet been deemed safe for use in clinical practice. The goal of precision medicine can only be achieved through the integration of tissue architecture with various -omics approaches, such as genomics, transcriptomics, proteomics, and more. By combining all these omics data in situ, alongside clinical information, we can generate a wealth of information that can pave the way for precision medicine. Achieving this level of integration and analysis is only possible with the aid of AI. Our past experience with artificial intelligence tools did not yield the level of accuracy we had hoped for, leaving us dissatisfied. However, with the passage of time and the use of more recent software, we have observed extraordinary improvements in accuracy.
Our studies have also shown that working in synergy with AI enhances our capabilities. Collaboration is key to achieving better results. While AI performs exceptionally well in certain circumstances, there are also situations where it can make mistakes, and it is important to avoid prolonging any errors. This is why more general laws, such as GDPR, have been established to protect patients from the usage of AI alone. Colleagues in radiology have also recognised that autonomous systems can increase the risk of systemic errors. Therefore, it is essential not to use AI tools in isolation. Synergy is the best approach to ensure that we work with AI effectively, while keeping patient safety as a top priority. It is essential for us to have explainability of artificial intelligence in medicine, particularly in pathology. We need to have a thorough understanding of the algorithms we use, of what we are seeing, and of how we can control this. Without such knowledge, we would be relying on faith or religion, rather than science. Therefore, we should take advantage of these new tools not only to enhance our understanding of how to use them, but also to gain insights into the diseases we study.
Prof. Eloy’s experience using a commercial software with her team was very positive, and they published the results in Virchows Archiv. They tested Paige Prostate on a number of cases and found that it did not improve accuracy in diagnosing cancer or enhance diagnostic skills. However, it did significantly reduce observation time by 22% in both negative and cancer cases, while also reducing requests for immunohistochemistry by 21% and second opinions by 39%. This acceleration in the diagnostic process is highly relevant and warrants our attention. Although the software may not have other purposes on its own, AI’s ability to accelerate the workflow is valuable and should be considered for implementation.
In sum, we need to fully adopt digital pathology in our laboratory as it is crucial for the development of artificial intelligence and computational pathology. Without it, we impede the progress of pathology and hinder our patients’ access to important technology. Moreover, it is important to strive for a synergistic use of AI and pathology, where human pathologists and software complement each other and become stronger. As these algorithms mature for proper usage, they will offer impressive advancements for our patients.
AI applications in colorectal cancer
Jakob Nikolas Kather is Professor of Clinical Artificial Intelligence, Else Kröner Fresenius Center for Digital Health, Technical University Dresden, Dresden, Germany. The Clinical Artificial Intelligence research group is a diverse team of scientists with a clinical perspective on health and disease. They use artificial intelligence and computational modelling, to extract valuable information from clinical data, with a primary focus on precision oncology, solid tumours, and immunotherapy. They are global leaders in predicting clinically relevant tumour characteristics using routinely available histopathology slides.
Patients generate various types of data in clinical settings. There are two main categories of data: structured data, which includes organised information such as blood pressure values, which can be entered into a spreadsheet, and unstructured data, which is more complex and consists of images and free text. While structured data can be analysed with simple machine learning methods or even manually, unstructured data requires more advanced techniques to be effectively processed. It is quite astonishing to note that prior to the 1990s, it was extremely challenging to train computers to work with images and text, and there were no practical solutions to teach computers to automatically analyse images. However, this has drastically changed over time. Since 2012, we have convolutional neural networks that can analyse images with human expert-like performance. Moreover, with the advent of large language models in 2021, computers can now efficiently analyse any text with human-level accuracy. These advanced technologies can be utilised to address clinical issues.
Specifically focussing on image data, in oncology we have a diverse range of images available for our patients. Skin lesion photos are a common type of image, and a paper published in Nature in 2017 was among the first studies to employ modern AI techniques, such as convolutional neural networks, to analyse these images for skin cancer diagnosis. Additionally, we have endoscopy, radiology, and histopathology image data at our disposal. What is particularly fascinating about histopathology is that the routinely scanned slides are incredibly large in size and contain an abundance of information, far exceeding that of a whole chest CT series with multiple slices.

Prof. Kather presented some examples of colorectal cancer detection using endoscopy. Identifying polyps during colonoscopies is a repetitive task that can be automated with convolutional neural networks. In fact, there are currently at least four systems available in Europe that can be purchased and utilised in clinical settings to detect polyps. Artificial intelligence has become the clinical state-of-the-art in preventing and screening for colorectal cancer. Likewise, in histopathology, several AI-based algorithms have been approved for clinical use, either by the FDA in the US or the CE IVDR regulation in the European Union. Numerous vendors sell these AI algorithms, and the only thing that is currently lacking is the digital infrastructure in pathology departments in Germany and other nations to enable their deployment. However, these AI systems have received clinical approval and can be implemented in histopathology as part of routine clinical practice. The Clinical Artificial Intelligence research group, being an academic research team, does not engage in the creation of any products, but rather aims to generate innovative ideas that may eventually be incorporated into a product in 8 to 10 years or more. Although this is a long-term process, occasionally things can progress very rapidly, and some of their concepts have already been used to inspire or fuel products within just three to four years.
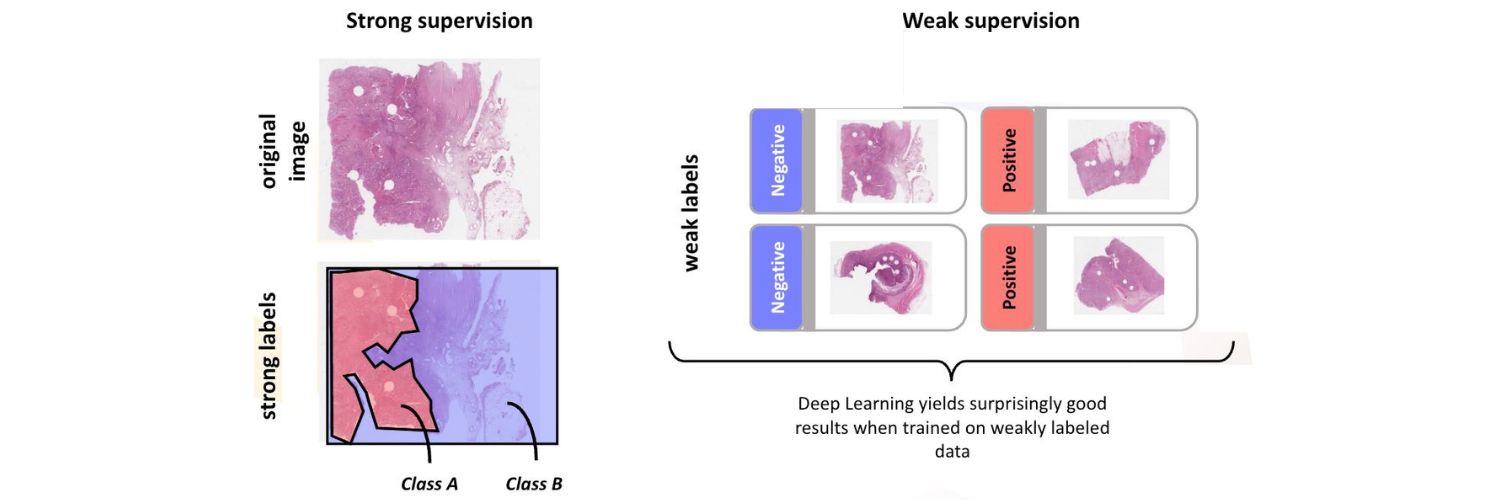
When considering the application of artificial intelligence in histopathology, we typically identify two different types of problems. The first is strongly supervised prediction problems, in which annotated image data is used to train machine learning algorithms. In this method, pathologists manually annotate the images, marking regions that are known to contain tumour tissue. The annotations serve as strong labels for the machine learning algorithm, indicating which pixels in the image correspond to tumour tissue and which do not. By using these strongly supervised labels, the machine learning algorithm can learn to identify and classify tumours tissue with high accuracy. As an alternative, we often prefer to use weak supervision, where the label is typically assigned to the entire slide, rather than individual pixels within the slide. For example, suppose we have a dataset of 10,000 images of prostate biopsies, and know that 5,000 of them contain cancer somewhere in the image, while the other 5,000 are benign. In this case, we would have an image-level label for each of the 10,000 images indicating whether it is cancerous or benign, rather than individual pixel-level labels. Deep learning systems can now be trained on these types of images and still perform very well, which is why we tend to favour this approach. One of the benefits of weakly supervised prediction methods is that it is easy to change the label being predicted. For example, instead of predicting which patients have cancer and which do not, we could input survival data and use that as the label for prediction. By doing so, we can train our deep learning system to identify more complex biomarkers in the slides, which is incredibly exciting.
Prof. Kather and his group have utilised the weakly supervised prediction approach in much of their research. In 2019, they conducted a study using deep learning to forecast microsatellite instability from histopathology images of colorectal cancer, endometrial cancer, and gastric cancer. The outcomes demonstrated that this method works well. It was not surprising since we already knew that microsatellite instability in these types of tumours causes particular phenotypes, but it was significant as it demonstrated that we could predict genetic changes directly from H&E pathology slides. Since then, the team has extended their weakly supervised prediction method to include many other biomarkers beyond MSI. The method was published in 2019 and has since led to regulatory approval of a related product by Owkin. The product uses the method to predict the microsatellite instability status with a certain accuracy from histopathology slides in colorectal cancer, and it can be used as a pre-screening tool before definitive testing. Although there is a conflict of interest here, the approval of this method for diagnostic routine in Europe is a significant milestone. Hopefully, it will be extended to include many other biomarkers in the future. Recently, the team performed a large-scale analysis of multiple biomarkers in various tumour types. They examined point mutations in relevant genes across multiple tumour types to see if they could predict mutations in these genes directly from H&E histopathology using deep learning. The researchers found that this method works well for predicting clinically relevant genetic alterations. They also noted that the genotype of a tumour is reflected in its phenotype and, in some cases, can be predicted using deep learning methods just by analysing the phenotype.
A related application of the same technology involves predicting survival in colorectal cancer. In recent years, various research groups, including Prof. Kather’s own, have used deep learning methods to build systems that can predict overall survival or relapse after curative surgery based on histopathology images. Again, this is not surprising because we know, for example, that if a patient has a lot of lymphocytes in their tumour and are operated in curative intent, their prognosis is better because the tumour was quite immunogenic, and they are less likely to get a relapse. So, for example, just the abundance of lymphocytes is a good prognostic marker in colorectal cancer, but there are many others, and by analysing features such as stroma phenotypes, differentiation etc., these deep learning systems can predict the likelihood of relapse and survival. From a researcher point of view, these methods have the potential to not only be used as clinically relevant tools, but also to make scientific discoveries. Particularly interesting is the ability of these methods to visualise the spatial heterogeneity of mutations in tumours. In one of the studies conducted by the group, they demonstrated that these systems can not only predict mutations in a given gene from histopathology, but can also generate spatial prediction heat maps that are consistent with spatial sequencing methods.
Multimodal models are a significant topic in the field of AI, where various types of data are combined to create a single model for prediction. Prof. Kather contributed to a study led by Sebastian Foersch from Mainz, Germany, developing and validating a deep learning model. The model takes into account both H&E slides and immunohistochemistry slides of colorectal cancer to predict survival and relapse. In general, deep learning methods can be utilised on histopathology slides of various tumours, including colorectal cancer, for two distinct purposes. One is to develop clinical biomarkers that may eventually gain regulatory approval and be used in routine clinical practice. The other is for scientific discovery. The team recently published two reviews where these ideas are discussed in more in detail (https://www.nature.com/articles/s43018-022-00436-4 and https://aacrjournals.org/clincancerres/article/29/2/316/713971/Facts-and-Hopes-on-the-Use-of-Artificial).
Looking at the overall field, there has been an exponential growth in technical capabilities for analysing unstructured data, such as image and text data. Prior to 2012, classical statistics and some machine learning methods worked well for linear regression and predicting future developments in time series. However, they were not suitable for analysing image data. The development of convolutional neural networks between 2012 and 2021 allowed for the extraction of value from image data. Since 2022, the field has taken another turn, with much larger and more capable models that can generate images and make predictions without being trained on a specific problem, known as zero-shot predictions. These advancements are only the beginning, and in the upcoming years, there will be further developments in AI methods. The role of medical professionals and researchers will be to ask the right biomedical questions to utilise these advancements effectively.
Digital pathology biomarkers for breast cancer
Arvydas Laurinavicius is Professor of Pathology at Vilnius University and Director of the National Centre of Pathology, Affiliate of VULSK, Vilnius, Lithuania. Continuing on the topic of digital transformation in pathology, we can see two major benefits. The first is to enhance the digital workflow by improving the manner and method in which we work. The second involves obtaining, or computing, new knowledge from the rich data available. Thinking about what type of new information we can retrieve from images, applications can be categorised into several groups. One group addresses technical support in pathology, such as object detection and IHC quantification. Another one deals with the automation of the pathologist’s capabilities, such as tumour detection, subtyping, and grading. However, the most exciting aspect of computational pathology lies in its ability to extract visual information that cannot be detected by pathologists as human beings. For instance, computational pathology can be used to predict genetic alterations, survival, and response to therapies.
There are two basic pathways for obtaining new information, one of which is more traditional and involves image analysis, image analytics, and statistical disease modelling. The other involves using deep learning to extract features. The first method is explicit, hypothesis-driven, human engineered, while the other is implicit, hypothesis-generating, and presents issues with explainability. Of course, there may be a combination of both pathways. With this feature extraction method, we aim to predict diagnosis, prognosis, response to therapies and all of the other features of tissue pathology. Basically, we seek to extract and measure hidden or subvisual pathology features in the spatial context of tissue microenvironment. Prof. Laurinavicius presented two hypothesis-driven, image-based, computational models or digital biomarkers, which help us to detect and measure intratumour heterogeneity and to assess tumour-host interaction.

Why is intratumour heterogeneity important? Tumours are comprised of various cancer cell clones, some of which are more aggressive, some may be responsive to certain therapies, while others may be resistant. This heterogeneity poses a significant challenge for targeted therapies, as attacking one type of cell may leave others unaffected and able to proliferate, ultimately resulting in patient harm. Looking at a typical scenario, the pathologist needs to identify a hotspot of proliferative activity in a breast cancer sample. However, there are different definitions of what constitutes a hotspot, and it can be a sub-visual feature that is difficult for humans to identify. This can lead to sampling errors when trying to measure the most proliferative part of the tumour. In conventional pathology we use a tube microscope to make semi-quantitative assessments and produce one or two figures of the whole tumour. A while ago, Prof. Laurinavicius and his team speculated about whether it would be possible for a robot to perform multiple machine readings of local proliferation rates. To accomplish this, they utilised a hexagonal grid to sub-sample the local proliferation rates, and obtained more extensive data. The reason for using hexagons is that they are the most compact regular polygons that can tile the plane, resulting in more effective circle coverage. Also, they provide uniform distances between cells, which is crucial for measuring Haralick texture entropy, which in this case is surface measures of intratumoural heterogeneity. The team obtained a comprehensive data set from just one Ki67 slide, with over 20 indicators representing different properties of what they were measuring. It is even possible to map back the local proliferation rates to see where they are located within the tumour. They also introduced the concept of a Pareto hotspot, which identifies the 20% hottest and most proliferative areas in the tissue. Additionally, it is also possible to visualise histograms that show the roughness of the proliferative surface of the tumour and provide quantitative expressions of these features. This helps us to understand the heterogeneity of the tumour.
The researchers later tested this model on a Nottingham breast cancer patient cohort to predict patient survival. They had hypothesised that the proliferation percentile or Pareto hotspot would be the most useful predictor of patient survival. However, they were surprised to find that the bimodality of heterogeneity of proliferation was actually the most powerful predictor. The data also suggests that intratumour heterogeneity may be more significant than the level of biomarker expression in predicting patient outcomes. Next, Prof. Laurinavicius and his group looked at a patient cohort in hormone receptor-positive cancer and investigated six units of chemistry biomarkers. They used prognostic modelling to create a multiple regression model – the Cox regression model – that relied exclusively on immunohistochemistry data. No clinical or pathology data was required for this model. The model is based on three independent predictors: proliferation bimodality, immune response, and the surprising finding that higher progesterone heterogeneity is associated with better survival. High progesterone entropy or heterogeneity appears to be a feature of better survival, while low or high expression rates are associated with less favourable outcomes.
Moving on to the next model presented by Prof. Laurinavicius, the tumour-host interaction has become increasingly important in the age of precision immuno-oncology. Modern immunotherapies have demonstrated added value in terms of improving long-term patient survival, by highlighting the significance of understanding the mechanisms of this interaction. There are numerous methods to measure immune cells, or tumour immune contexture, in the tissue. Some studies measure distances between tumour cells and lymphocytes, clustering of lymphocytes. Other methods include assessing individual distances between different cells, multiplexing data, detecting the immunotherapy invasive margin, and analysing the spatial distribution of infiltrating immune cells. In a previous study, the team investigated where the tumour-host interaction happens and hypothesised that it does not occur along a linear or ribbon-like structure, but rather in an area, which they termed interaction or interface zone, a 2D projection of a 3D tumour stroma interface. To identify the edge of this zone, they applied a hexagonal grid and used single immunohistochemistry for CD8. They then utilised the HALO AI tool for tumour stroma segmentation and positive cell detection, followed by a computational assessment of the image analysis outputs. The process involves two main steps. First, we explore a cell, the contents of each hexagon and the surroundings of the hexagons to compute the probability of “interfaceness” of each hexagon. The resulting edges indicate the areas of highest probability. Subsequently, we analyse patient information from the host, stroma, and deeper regions of the tumour. This enables us to compute the local or rank densities of tumour-infiltrating lymphocytes. Various tumours display distinct profiles; some exhibit a drop in density upon entering the tumour, while others exhibit the opposite effect. Additionally, certain tumours feature lymphocytes that stop at the edge and do not penetrate the tumour. The team applied several indicators, such as the centre of mass, to quantitatively assess this phenomenon. These indicators, which they termed immunogradient indicators, reflect the propensity of lymphocyte infiltration into the tumour. A heat map shows the significant and selective sampling area where we can calculate these immunogradient indicators. The researchers tested this approach in parallel on patients with breast cancer and colorectal cancer and obtained similar results, with the new indicators having high prognostic significance.

To illustrate one of these features we can look at the cohort of patients with early hormone receptor-positive breast cancer, which is a well-managed disease. If we examine the survival rate of these patients five years after undergoing surgical excision, we see that 92% of them have survived. But what happened next? Those patients who had low immunogradient at the time of surgery, had a much worse survival rate, 55% compared to 87%. This highlights the importance of assessing lymphocyte distribution in this non-aggressive type of cancer, which predicts long-term survival. Another interesting phenomenon was found in CD1 images of a patient cohort of HER2 borderline FISH-negative patients, revealing three independent prognostic features that, when combined, allowed for powerful patient stratification. This demonstrates how one image can provide valuable prognostic information by retrieving multiple biomarkers and combining them into a single model. Additionally, intratumour heterogeneity of HER2 membrane completeness and oestrogen receptor were also features associated with better patient survival in other models of the same patient cohort.
Going back to the concept of intratumour heterogeneity, which may be equally or even more important than the level of biomarker expression, Prof. Laurinavicius quoted from a study which explored these features in the genetic testing of various tumours: “Quantification of ITH is a key measure of tumour evolution.” This is a universal prognostic biomarker, albeit potentially non-linear. To summarise, these findings are consistent with similar results found in other solid tumours. The research group has investigated over 800 patients and the message that can be inferred from this is that spatial heterogeneity may be outperforming the level of biomarker expression in various situations. Measuring gradient for spatial and directional distribution of immune cells at the tumour-stromal interface is more informative than absolute TIL densities in the tumour microenvironment. Furthermore, it can also be demonstrated that IHC-based models can be achieved, which commonly outperform the conventional parameters used in clinical practice today.
During the panel discussion, the implementation of digital pathology was discussed, with a focus on the challenges that must be addressed. These obstacles include changes to structure, mental adaptation, cost, integration of image and laboratory management systems, cultural transformation, and shortages of pathologists and lab technicians. The speakers emphasised that political will and investment are necessary for success. Additionally, the potential of artificial intelligence in pathology was discussed in relation to patient stratification in clinical trials and the development of new biomarkers. Prof. Pruneri’s take home message was that digital pathology is likely to become a crucial tool in medicine, but its implementation requires diversifying the team of professionals involved and understanding ethical and regulatory issues. The cost of digital pathology is a significant challenge, and centralising resources and building networks of labs may be a solution. It is also essential to share data with companies while at the same time protecting patients. And lastly, labs that have already focused on collecting and managing large amounts of data, particularly genomic data and other omics data (such as proteomics or metabolomics), may have a higher chance of successfully implementing digital pathology. This is because they likely already have the necessary infrastructure in place, such as computing clusters and a team of informaticians and professionals who are familiar with managing large data sets.
Artificial Intelligence in Cancer Care Educational Project
Artificial intelligence has given rise to great expectations for improving cancer diagnosis, prognosis and therapy but has also highlighted some of its inherent outstanding challenges, such as potential implicit biases in training datasets, data heterogeneity and the scarcity of external validation cohorts.
SPCC will carry out a project to develop knowledge and competences on integration of AI in Cancer Care Continuum: from diagnosis to clinical decision-making.
This is the report of the sixth webinar part of the “Artificial Intelligence in Cancer Care Educational Project”.
Click here to read the report of the first webinar.
Click here to read the report of the second webinar.
Click here to read the report of the third webinar.









